
Fei-Fei Li’s New AI Model Redefines Distillation: Challenging DeepSeek at Just US$14?

Fei-Fei Li
Image Source: Stanford University
(The image has been horizontally extended for design presentation purposes.)
Fei-Fei Li, a titan of artificial intelligence, has unveiled s1-32B—a reasoning model distilled for a mere US$14 in cloud costs—igniting a fresh debate over AI’s economic and technical frontiers. Detailed in a January 31, 2025, research paper, this 32-billion-parameter innovation outstrips OpenAI’s o1 in key benchmarks, but its true rival may be DeepSeek’s R1, the Chinese chatbot claimed for its US$5.6 million budget.
Model s1-32B: Distillation’s New Benchmark
Li, leading a team from Stanford and the University of Washington, distilled s1-32B from Alibaba’s open-source Qwen2.5-32B-Instruct model, fine-tuning it on a 1,000-example s1K dataset in 26 minutes using 16 Nvidia H100 GPUs on Alibaba Cloud. The model excels in reasoning—beating o1-preview by up to 27% on 2024 AIME math problems—thanks to a “budget forcing” technique that boosts accuracy by prompting self-correction at test time. This leap in distillation efficiency slashes costs far below DeepSeek’s V3 / R1, which, while lean at US$5.6 million, targets broader chatbot capabilities.
DeepSeek’s R1, launched in January 2025, stunned with its low training budget and rapid U.S. app store ascent. Yet, s1-32B’s razor-thin price tag—over 100,000 times cheaper—raises the stakes, pushing distillation to unprecedented limits. Li’s team credits their curated dataset and lightweight scaling, contrasting DeepSeek’s broader algorithmic and hardware optimizations.
Cost Estimates: A Range of Perspectives
Interpretations of the cloud cost for training the s1‑32B model vary across industry outlets. Panewslab.com and The Verge both report that the total cloud cost for training s1‑32B was under US$50. Tim Kellogg’s blog, however, estimates a significantly lower cost of around US$6—though this appears inconsistent with typical cloud pricing. Current rental rates from providers such as Hyperstack, CUDO Compute, RunPod, and Nebius AI Cloud average around US$2 per H100 GPU per hour. Using this rate, the estimated cost for 16 GPUs running for 26 minutes is approximately US$14 (16 × 2 × 26/60), which aligns more closely with the estimate from The Economic Times.
[Read More: Can a US$5.6 Million Budget Build a ChatGPT-Level AI? ChatGPT o3-mini-high Says No!]
Fei-Fei Li: A Visionary’s Journey
Stanford AI pioneer Fei-Fei Li, awarded the 2025 Queen Elizabeth Prize for Engineering, continues to shape the future of artificial intelligence. Born in Beijing in 1976, Li immigrated to the U.S. at 15, working in a Chinese restaurant while excelling academically. She earned a physics degree from Princeton in 1999 and a Ph.D. in electrical engineering from Caltech in 2005. In 2009, she co-created ImageNet, revolutionizing computer vision and paving the way for modern deep learning. Now a professor at Stanford and co-founder of World Labs, a startup focused on AI-driven understanding of the physical world, Li ties her human-centered AI philosophy to her immigrant journey in her memoir The Worlds I See.
[Read More: DeepSeek AI Faces Security and Privacy Backlash Amid OpenAI Data Theft Allegations]
Qwen’s Role: Open vs. Elite
Model s1-32B is built on Qwen2.5-32B-Instruct, Alibaba’s open-source 32-billion-parameter model, released in September 2024 and trained on 5.5 trillion tokens. It excels in coding, scoring 84.0 on the MBPP (Massive Multitask Programming Problems) test, and in mathematics, achieving 83.1 on the MATH benchmark. Meanwhile, DeepSeek’s R1 has acknowledged using distillation for its development but has not disclosed the source model. OpenAI, now working with the U.S. government, is investigating whether DeepSeek leveraged ChatGPT for distillation, as unusual behaviour suggesting potential violations of OpenAI’s usage terms has been detected.
[Read More: DeepSeek’s 10x AI Efficiency: What’s the Real Story?]
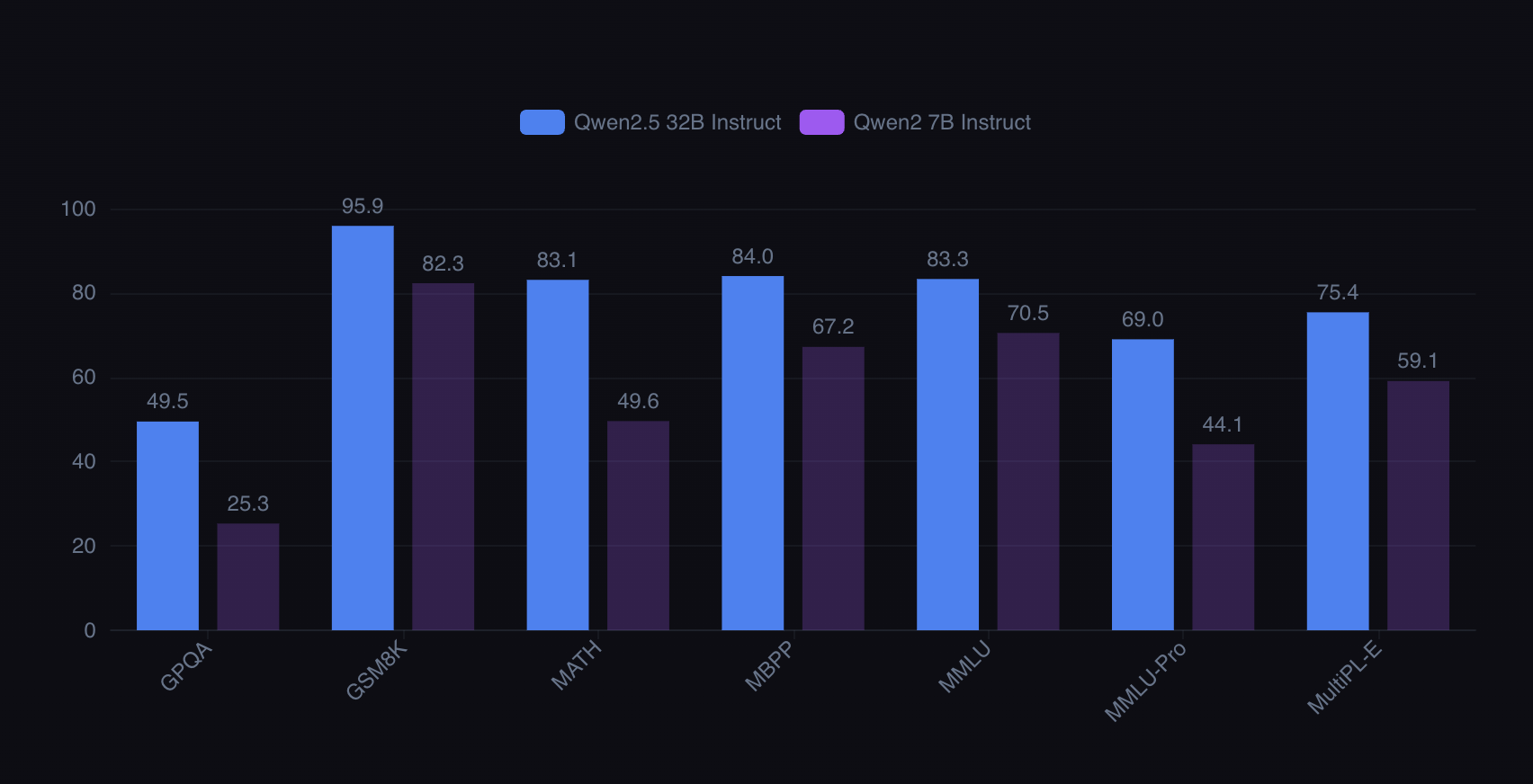
Image Source: LLM Stat
On the other hand, Qwen2.5-Max, a Mixture-of-Experts powerhouse launched on January 28, 2025, boasts over 20 trillion tokens and a leading 89.4 score on the Arena-Hard benchmark. However, its API-only access contrasts with the open nature of 32B-Instruct—fueling both Li’s and DeepSeek’s distillation advances.
[Read More: Why Did China Ban Western AI Chatbots? The Rise of Its Own AI Models]
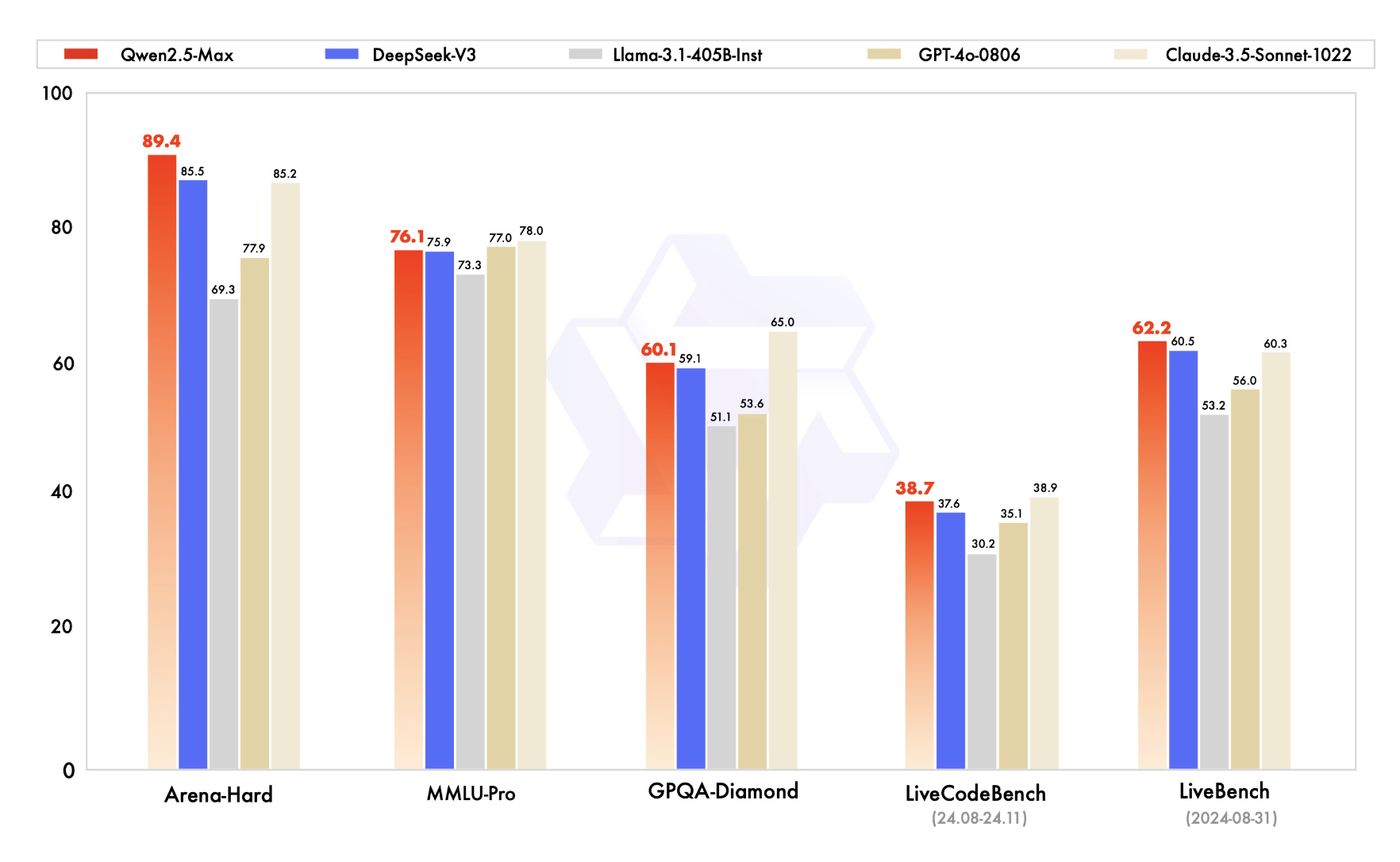
Image Source: QwenLM GitHub
Industry Stakes: A Cost-Efficiency Race
Analysts see an emerging rivalry in AI distillation. DeepSeek’s R1 made headlines after its release coincided with a significant tech market selloff, erasing over $1 trillion in market capitalization, with Nvidia alone losing nearly $600 billion on January 27, 2025. Meanwhile, Fei-Fei Li’s s1-32B, though narrower in scope, demonstrates an alternative approach to cost-efficient AI. While discussions persist about whether DeepSeek leveraged proprietary models, no concrete evidence has been disclosed. In contrast, Li’s model, built transparently on Alibaba’s open-source Qwen2.5-32B-Instruct, avoids similar scrutiny. The true cost of AI remains a point of debate.
[Read More: Apple-Alibaba AI Alliance: Boosting Revenue or a Privacy Concern?]
Source: Stanford University, QE Prize, arXiv, AP News, The Wall Street Journal, Princeton Alumni, Reuters, Qwen, Hugging Face, CCN











