
s1-32B AI Breakthrough: Simple Reasoning Rivals OpenAI o1

Image Credit: Immo Wegmann | Splash
A team of researchers has introduced a groundbreaking approach to enhancing artificial intelligence reasoning capabilities, potentially redefining how language models address complex challenges. Detailed in a new paper titled "s1: Simple Test-Time Scaling", this advancement emerges from a collaboration involving Stanford University, the University of Washington, and other leading institutions. The study presents s1-32B, a model that challenges industry heavyweights like OpenAI’s o1 with a strikingly efficient and transparent methodology.
[Read More: ChatGPT Marks Two Years as Academic Tool: Boosting Productivity Amidst Concerns]
A Lean Approach to AI Reasoning
At the heart of this innovation is its minimalist design. Departing from the norm of leveraging vast datasets and elaborate training processes, the team behind s1-32B achieved impressive results with a mere 1,000 meticulously chosen questions. These questions, bundled with detailed reasoning traces into a dataset dubbed s1K, were selected based on their quality, difficulty, and diversity. Using this compact dataset, the researchers fine-tuned an existing model, Qwen2.5-32B-Instruct, in just 26 minutes on 16 NVIDIA H100 GPUs—a fraction of the computational effort typically required by competitors.
Lead author Niklas Muennighoff, alongside co-authors Zitong Yang, Weijia Shi, and notable Stanford researcher Fei-Fei Li, emphasized their aim to identify the simplest route to improving AI performance during test time, when additional computation refines responses. Fei-Fei Li, a prominent figure known for her work on ImageNet and leadership in human-centered AI, joins a roster of distinguished contributors, underscoring the project’s academic weight. Their technique, termed "budget forcing", adjusts the model’s thinking duration by either terminating it early or prolonging it with prompts like "Wait" to deepen analysis. This method enables s1-32B to scale its performance dynamically, delivering up to a 27% edge over OpenAI’s o1-preview on rigorous math competition benchmarks such as MATH and AIME24.
[Read More: Agentic AI in 2025: The Rise of Autonomous AI Agents by OpenAI, Microsoft and Nvidia]
Outperforming the Giants
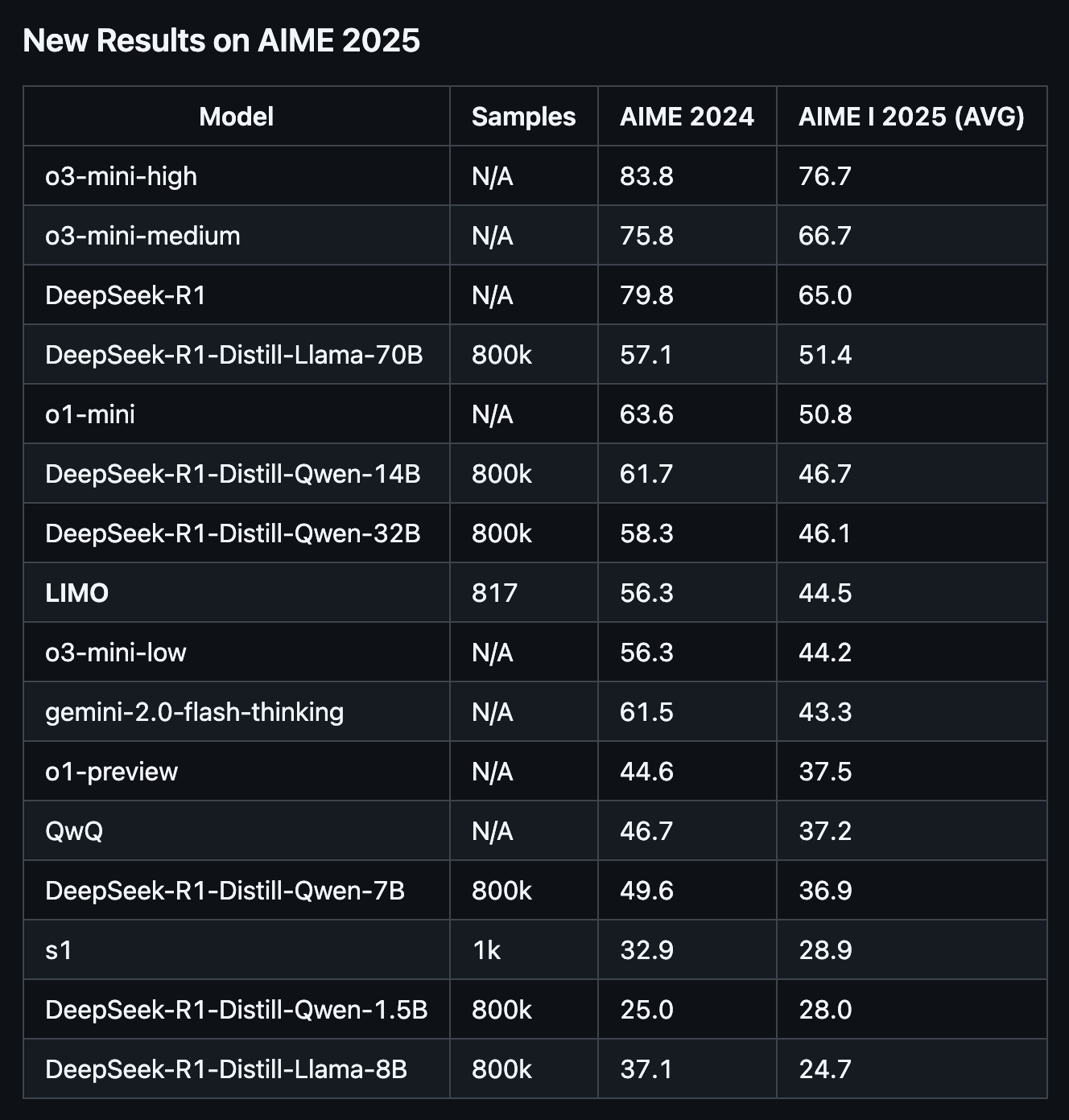
The performance metrics of s1-32B are compelling, but how does it compare to the latest models like OpenAI’s o3-mini and DeepSeek’s R1? On the AIME24 dataset—30 problems from the 2024 American Invitational Mathematics Examination — s1-32B scored 56.7%, outperforming o1-preview’s 44.6%. OpenAI’s o3-mini (high effort) leads with 83.8%, closely followed by DeepSeek’s R1 at 79.8%. On MATH500, a set of 500 competition-level math problems, s1-32B achieved 93%, slightly behind o1’s 94.8%. R1 excels with 97.3%, benefiting from its reinforcement learning advantage.

Source: arXiv
Source: GitHub
In science, tested on the GPQA Diamond set of PhD-level questions in biology, chemistry, and physics, s1-32B scored 59.6 percent, trailing o1’s stronger 77.3 percent. R1 achieved 71.5 percent, a solid performance for an open-source model, while o3-mini at lower effort levels lags at 60 percent. The full o3, however, reaches 87.7 percent, cementing OpenAI’s lead in scientific reasoning. Launched on January 31, 2025, o3-mini prioritizes efficiency, delivering STEM-focused reasoning at 93 percent lower cost than o1-mini, according to OpenAI’s claims. While o3-mini and R1 outperform s1-32B in raw scores, s1-32B’s results remain notable given its significantly smaller training dataset compared to OpenAI and DeepSeek.
[Read More: DeepSeek’s R1 Model Redefines AI Efficiency, Challenging OpenAI GPT-4o Amid US Export Controls]
Budget Forcing: Optimizing Test-Time Compute
The key to s1-32B’s success is something called budget forcing, which is like giving the AI a time limit for thinking. Imagine you're taking a test, and you’re told to answer as quickly as possible. You might make mistakes because you're rushing. But if you're allowed more time, you can double-check and fix errors.
For s1-32B, the "budget" refers to the number of steps the AI takes before giving an answer. If you tell it to think for a short time, it gives a fast response. But if you say, "Wait", it takes more time to reconsider and often corrects mistakes.
For example, when asked to count the letter "r" in "raspberry", the AI first gave the wrong number. But when given more time to think, it checked again and got it right (3 "r"s). This method helps the AI be more accurate while still being efficient when needed.
This step-by-step thinking approach (budget forcing) is different from majority voting, where the AI generates multiple answers and picks the most common one. For example, if five AI models answer a math question and three say "144" while two say "140," the final answer would be "144" because it appears the most. While this method reduces mistakes, it requires more computing power since multiple responses must be generated.
The researchers found that budget forcing performed better—instead of generating multiple answers, the AI took more time to refine a single answer, improving accuracy. However, there is a drawback: if the AI "overthinks" for too long, it may get stuck repeating the same ideas without actually improving the answer. The team sees this as an area to refine in future updates.
[Read More: Repeated Server Errors Raise Questions About DeepSeek's Stability]
Transparency and Accessibility
In a field often marked by secrecy, s1-32B stands out for its openness. Unlike OpenAI’s o1 series, which keeps its methods proprietary, the s1-32B team has publicly released the model, dataset, and code on GitHub under the Apache 2.0 license. This contrasts with OpenAI’s closed-source approach and aligns with efforts like DeepSeek’s R1, which is also open-source but under the MIT License. By embracing open-source development, s1-32B and DeepSeek R1 could help level the playing field, enabling smaller entities to advance AI without relying on the massive infrastructure of tech giants.
While s1-32B doesn’t dominate across all metrics, its efficiency and transparency are poised to influence the AI landscape. The paper’s impact statement reflects this ambition:
"Our work aims to push the frontier of reasoning in a fully open manner, fostering innovation and collaboration to accelerate advancements that ultimately benefit society".
[Read More: OpenAI Unveils o3: Pioneering Reasoning Models Edge Closer to AGI]
The Data Behind the Success
The creation of s1K was a deliberate process. From an initial pool of 59,029 questions sourced from math Olympiads, PhD exams, and other repositories, the team distilled 1,000 based on three pillars: difficulty (to stump weaker models), diversity (covering 50 domains from geometry to quantum theory), and quality (filtering out formatting errors). Ablation studies validated this approach — randomly picking 1,000 samples slashed AIME24 performance by about 30%, while using the full 59,000 offered minimal gains over s1K, underscoring the power of selective curation.
Distilled from Google’s Gemini Flash Thinking Experimental API, s1K exemplifies a shift toward smarter data use over sheer volume, a strategy that could inspire future AI training efforts.
[Read More: Elon Musk’s Grok 3: The Strongest AI Ever Built?]
Challenges and Opportunities
Despite its strides, s1-32B faces hurdles. Performance plateaus with excessive test-time compute, limited by the model’s context window and propensity for repetition. The team suggests exploring hybrid solutions, such as integrating budget forcing with reinforcement learning or parallel scaling like REBASE, which showed potential in further elevating accuracy.
The AI research community is taking note. Experts posit that refining budget forcing to sustain gains at higher compute levels could transform test-time strategies. For now, s1-32B exemplifies how simplicity can yield sophistication, proving that a lean, open approach can challenge the best in AI reasoning.
[Read More: Fei-Fei Li’s New AI Model Redefines Distillation: Challenging DeepSeek at Just US$14?]
Source: arXiv, GitHub, Venture Beat, OpenAI


















